Hi! My name is Nhut Nguyen. I am a software engineer and a writer in Copenhagen, Denmark.
Learn more about me at nhutnguyen.com
Problem statement
Every valid email consists of a local name and a domain name, separated by the '@' sign. Besides lowercase letters, the email may contain one or more '.' or '+'.
For example, in "alice@leetcode.com", "alice" is the local name, and "leetcode.com" is the domain name.
If you add periods '.' between some characters in the local name part of an email address, mail sent there will be forwarded to the same address without dots in the local name. Note that this rule does not apply to domain names.
For example, "alice.z@leetcode.com" and "alicez@leetcode.com" forward to the same email address.
If you add a plus '+' in the local name, everything after the first plus sign will be ignored. This allows certain emails to be filtered. Note that this rule does not apply to domain names.
For example, "m.y+name@email.com" will be forwarded to "my@email.com".
It is possible to use both of these rules at the same time.
Given an array of strings emails where we send one email to each emails[i], return the number of different addresses that actually receive mails.
Example 1
Input: emails = ["test.email+alex@leetcode.com","test.e.mail+bob.cathy@leetcode.com","testemail+david@lee.tcode.com"]
Output: 2
Explanation: "testemail@leetcode.com" and "testemail@lee.tcode.com" actually receive mails.
Example 2
Input: emails = ["a@leetcode.com","b@leetcode.com","c@leetcode.com"]
Output: 3
Constraints
1 <= emails.length <= 100.1 <= emails[i].length <= 100.emails[i]consist of lowercase English letters,'+','.'and'@'.Each
emails[i]contains exactly one'@'character.All local and domain names are non-empty.
Local names do not start with a
'+'character.Domain names end with the
".com"suffix.
Solution 1: Removing the ignored characters
Do exactly the steps the problem describes:
Extract the local name.
Ignore all characters after
'+'in it.Ignore all
'.'in it.Combine the local name with the domain one to form the clean email address.
Code
#include<string>
#include<iostream>
#include<vector>
#include <unordered_set>
using namespace std;
int numUniqueEmails(vector<string>& emails) {
unordered_set<string> s;
for (auto e: emails) {
auto apos = e.find('@');
string local = e.substr(0, apos); // extract the local name
local = local.substr(0, local.find('+')); // ignore all characters after '+'
for (auto it = local.find('.'); it != string::npos; it = local.find('.')) {
local.erase(it, 1); // remove each '.' found in local
}
s.insert(local + e.substr(apos)); // combine local name with domain one
}
return s.size();
}
int main() {
vector<string> emails = {"test.email+alex@leetcode.com",
"test.e.mail+bob.cathy@leetcode.com",
"testemail+david@lee.tcode.com"};
cout << numUniqueEmails(emails) << endl;
emails = {"a@leetcode.com","b@leetcode.com","c@leetcode.com"};
cout << numUniqueEmails(emails) << endl;
emails = {"test.email+alex@leetcode.com","test.email.leet+alex@code.com"};
cout << numUniqueEmails(emails) << endl;
}
Output:
2
3
2
Complexity
Runtime:
O(N*M^2), whereN = emails.length,M = max(emails[i].length). Explanation: you loop overNemails. Then you might loop over the length of each email,O(M), to remove the character'.'. The removal might costO(M).Extra space:
O(N*M)(the set of emails).
Solution 2: Building the clean email addresses from scratch
The runtime of removing characters in std::string is not constant. To avoid that complexity you can build up the clean email addresses from scratch.
Code
#include<string>
#include<iostream>
#include<vector>
#include <unordered_set>
using namespace std;
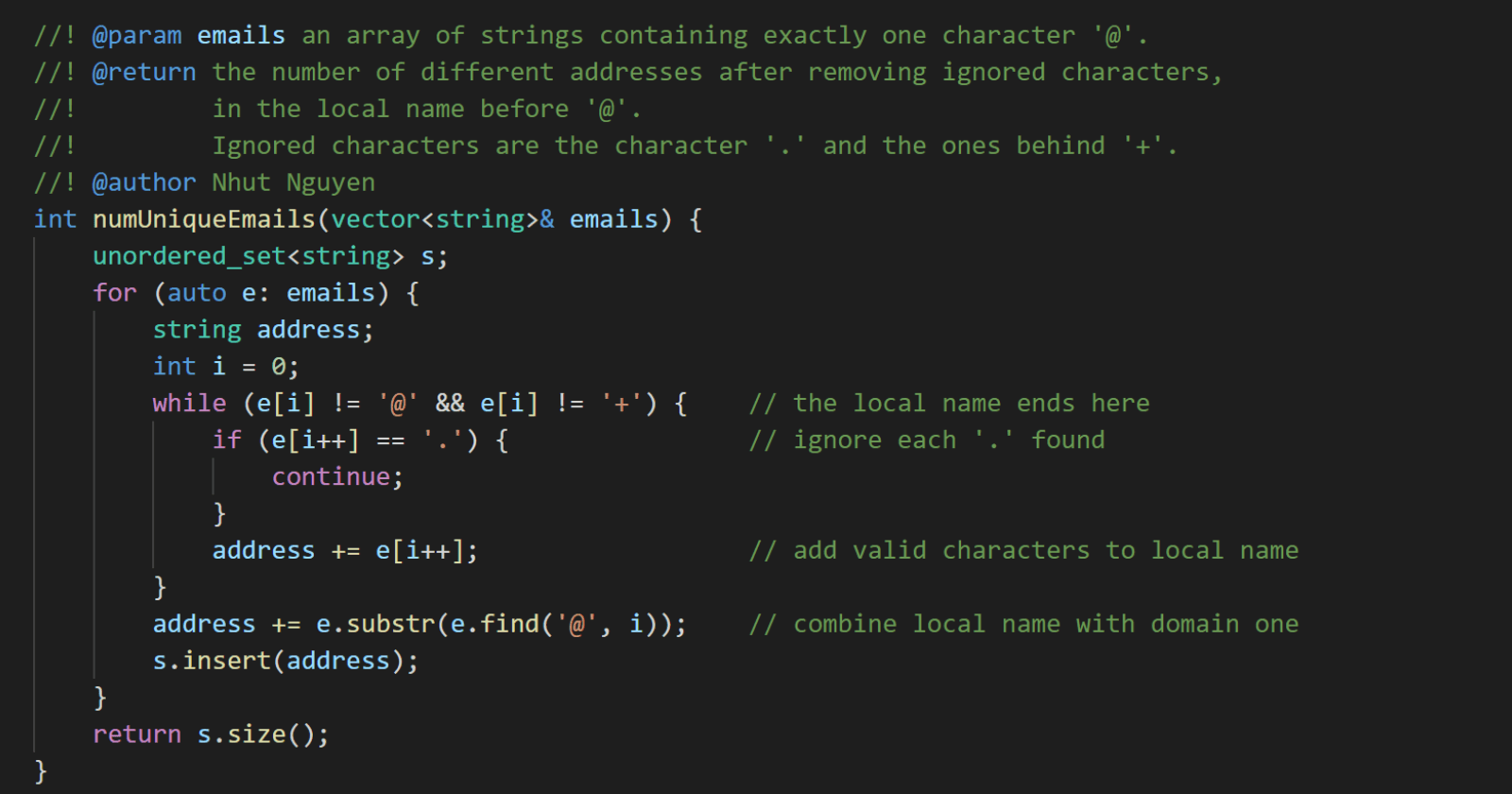
int numUniqueEmails(vector<string>& emails) {
unordered_set<string> s;
for (auto e: emails) {
string address;
int i = 0;
while (e[i] != '@' && e[i] != '+') { // the local name ends here
if (e[i++] == '.') { // ignore each '.' found
continue;
}
address += e[i++]; // add valid characters to local name
}
address += e.substr(e.find('@', i)); // combine local name with domain one
s.insert(address);
}
return s.size();
}
int main() {
vector<string> emails = {"test.email+alex@leetcode.com",
"test.e.mail+bob.cathy@leetcode.com",
"testemail+david@lee.tcode.com"};
cout << numUniqueEmails(emails) << endl;
emails = {"a@leetcode.com","b@leetcode.com","c@leetcode.com"};
cout << numUniqueEmails(emails) << endl;
emails = {"test.email+alex@leetcode.com","test.email.leet+alex@code.com"};
cout << numUniqueEmails(emails) << endl;
}
Output:
2
3
2
Complexity
Runtime:
O(N*M), whereN = emails.length,M = max(emails[i].length).Extra space:
O(N*M).
C++ Notes
- A
stringcan be concatenated with acharand anotherstringby+operator.
std::string address = "name";
address += '@'; // "name@"
address += "domain.com"; // "name@domain.com"
- string::substr(pos = 0, count = npos) returns the substring of length
countstarting from the positionposof the stringstring.
std::string address = "name@domain.com";
cout << address.substr(address.find('.')); // ".com"
cout << address.substr(0, address.find('@')); // "name"
- string::find(char, pos=0) returns the position of the first
charwhich appears in the stringstringstarting frompos.
High-performance C++
Do not use
std::setorstd::mapunless you want the keys to be in order (sorted). Use unordered containers like std::unordered_set or std::unordered_map instead. They use hashed keys for faster lookup.Do not blindly/lazily use
string.find(something). If you know where to start the search, usestring.find(something, pos)with a specificpos.
References
Thanks for reading. Feel free to share your thought about my content and check out my FREE book “10 Classic Coding Challenges”.